Data Portals
Pyomo’s DataPortal
class standardizes the process of constructing model instances by
managing the process of loading data from different data sources in a
uniform manner. A DataPortal object can load data from the
following data sources:
TAB File: A text file format that uses whitespace to separate columns of values in each row of a table.
CSV File: A text file format that uses comma or other delimiters to separate columns of values in each row of a table.
JSON File: A popular lightweight data-interchange format that is easily parsed.
YAML File: A human friendly data serialization standard.
XML File: An extensible markup language for documents and data structures. XML files can represent tabular data.
Excel File: A spreadsheet data format that is primarily used by the Microsoft Excel application.
Database: A relational database.
DAT File: A Pyomo data command file.
Note that most of these data formats can express tabular data.
Warning
The DataPortal
class requires the installation of Python packages to support some
of these data formats:
YAML File:
pyyamlExcel File:
win32com,openpyxlorxlrdThese packages support different data Excel data formats: the
win32compackage supports.xls,.xlsmand.xlsx, theopenpyxlpackage supports.xlsxand thexlrdpackage supports.xls.Database:
pyodbc,pypyodbc,sqlite3orpymysqlThese packages support different database interface APIs: the
pyodbcandpypyodbcpackages support the ODBC database API, thesqlite3package uses the SQLite C library to directly interface with databases using the DB-API 2.0 specification, andpymysqlis a pure-Python MySQL client.
DataPortal objects
can be used to initialize both concrete and abstract Pyomo models.
Consider the file A.tab, which defines a simple set with a tabular
format:
A
A1
A2
A3
The load method is used to load data into a DataPortal object. Components in a
concrete model can be explicitly initialized with data loaded by a
DataPortal object:
data = DataPortal()
data.load(filename='A.tab', set="A", format="set")
model = ConcreteModel()
model.A = Set(initialize=data['A'])
All data needed to initialize an abstract model must be provided by a
DataPortal object,
and the use of the DataPortal object to initialize components
is automated for the user:
model = AbstractModel()
model.A = Set()
data = DataPortal()
data.load(filename='A.tab', set=model.A)
instance = model.create_instance(data)
Note the difference in the execution of the load method in these two
examples: for concrete models data is loaded by name and the format must
be specified, and for abstract models the data is loaded by component,
from which the data format can often be inferred.
The load method opens the data file, processes it, and loads the
data in a format that can be used to construct a model instance. The
load method can be called multiple times to load data for different
sets or parameters, or to override data processed earlier. The load
method takes a variety of arguments that define how data is loaded:
filename: This option specifies the source data file.format: This option specifies the how to interpret data within a table. Valid formats are:set,set_array,param,table,array, andtransposed_array.set: This option is either a string or model compent that defines a set that will be initialized with this data.param: This option is either a string or model compent that defines a parameter that will be initialized with this data. A list or tuple of strings or model components can be used to define multiple parameters that are initialized.index: This option is either a string or model compent that defines an index set that will be initialized with this data.using: This option specifies the Python package used to load this data source. This option is used when loading data from databases.select: This option defines the columns that are selected from the data source. The column order may be changed from the data source, which allows theDataPortalobject to definenamespace: This option defines the data namespace that will contain this data.
The use of these options is illustrated below.
The DataPortal
class also provides a simple API for accessing set and parameter data
that are loaded from different data sources. The [] operator is
used to access set and parameter values. Consider the following
example, which loads data and prints the value of the [] operator:
data = DataPortal()
data.load(filename='A.tab', set="A", format="set")
print(data['A']) # ['A1', 'A2', 'A3']
data.load(filename='Z.tab', param="z", format="param")
print(data['z']) # 1.1
data.load(filename='Y.tab', param="y", format="table")
for key in sorted(data['y']):
print("%s %s" % (key, data['y'][key]))
The DataPortal
class also has several methods for iterating over the data that has been
loaded:
keys(): Returns an iterator of the data keys.values(): Returns an iterator of the data values.items(): Returns an iterator of (name, value) tuples from the data.
Finally, the data() method provides a generic mechanism for
accessing the underlying data representation used by DataPortal objects.
Loading Structured Data
JSON and YAML files are structured data formats that are well-suited for data serialization. These data formats do not represent data in tabular format, but instead they directly represent set and parameter values with lists and dictionaries:
Simple Set: a list of string or numeric value
Indexed Set: a dictionary that maps an index to a list of string or numeric value
Simple Parameter: a string or numeric value
Indexed Parameter: a dictionary that maps an index to a numeric value
For example, consider the following JSON file:
{ "A": ["A1", "A2", "A3"],
"B": [[1, "B1"], [2, "B2"], [3, "B3"]],
"C": {"A1": [1, 2, 3], "A3": [10, 20, 30]},
"p": 0.1,
"q": {"A1": 3.3, "A2": 3.4, "A3": 3.5},
"r": [ {"index": [1, "B1"], "value": 3.3},
{"index": [2, "B2"], "value": 3.4},
{"index": [3, "B3"], "value": 3.5}]}
The data in this file can be used to load the following model:
model = AbstractModel()
data = DataPortal()
model.A = Set()
model.B = Set(dimen=2)
model.C = Set(model.A)
model.p = Param()
model.q = Param(model.A)
model.r = Param(model.B)
data.load(filename='T.json')
Note that no set or param option needs to be specified when
loading a JSON or YAML file. All of the set and parameter
data in the file are loaded by the DataPortal>
object, and only the data
needed for model construction is used.
The following YAML file has a similar structure:
A: [A1, A2, A3]
B:
- [1, B1]
- [2, B2]
- [3, B3]
C:
'A1': [1, 2, 3]
'A3': [10, 20, 30]
p: 0.1
q: {A1: 3.3, A2: 3.4, A3: 3.5}
r:
- index: [1, B1]
value: 3.3
- index: [2, B2]
value: 3.4
- index: [3, B3]
value: 3.5
The data in this file can be used to load a Pyomo model with the same syntax as a JSON file:
model = AbstractModel()
data = DataPortal()
model.A = Set()
model.B = Set(dimen=2)
model.C = Set(model.A)
model.p = Param()
model.q = Param(model.A)
model.r = Param(model.B)
data.load(filename='T.yaml')
Loading Tabular Data
Many data sources supported by Pyomo are tabular data formats. Tabular data is numerical or textual data that is organized into one or more simple tables, where data is arranged in a matrix. Each table consists of a matrix of numeric string values, simple strings, and quoted strings. All rows have the same length, all columns have the same length, and the first row typically represents labels for the column data.
The following section describes the tabular data sources supported by Pyomo, and the subsequent sections illustrate ways that data can be loaded from tabular data using TAB files. Subsequent sections describe options for loading data from Excel spreadsheets and relational databases.
Tabular Data
TAB files represent tabular data in an ascii file using whitespace as a
delimiter. A TAB file consists of rows of values, where each row has
the same length. For example, the file PP.tab has the format:
A B PP
A1 B1 4.3
A2 B2 4.4
A3 B3 4.5
CSV files represent tabular data in a format that is very similar to TAB
files. Pyomo assumes that a CSV file consists of rows of values, where
each row has the same length. For example, the file PP.csv has the
format:
A,B,PP
A1,B1,4.3
A2,B2,4.4
A3,B3,4.5
Excel spreadsheets can express complex data relationships. A range is
a contiguous, rectangular block of cells in an Excel spreadsheet. Thus,
a range in a spreadsheet has the same tabular structure as is a TAB file
or a CSV file. For example, consider the file excel.xls that has
the range PPtable:
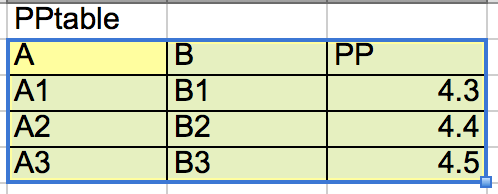
A relational database is an application that organizes data into one or more tables (or relations) with a unique key in each row. Tables both reflect the data in a database as well as the result of queries within a database.
XML files represent tabular using table and row elements. Each
sub-element of a row element represents a different column, where
each row has the same length. For example, the file PP.xml has the
format:
<table>
<row>
<A value="A1"/><B value="B1"/><PP value="4.3"/>
</row>
<row>
<A value="A2"/><B value="B2"/><PP value="4.4"/>
</row>
<row>
<A value="A3"/><B value="B3"/><PP value="4.5"/>
</row>
</table>
Loading Set Data
The set option is used specify a Set component that is loaded
with data.
Loading a Simple Set
Consider the file A.tab, which defines a simple set:
A
A1
A2
A3
In the following example, a DataPortal object loads data for a simple
set A:
model = AbstractModel()
model.A = Set()
data = DataPortal()
data.load(filename='A.tab', set=model.A)
instance = model.create_instance(data)
Loading a Set of Tuples
Consider the file C.tab:
A B
A1 1
A1 2
A1 3
A2 1
A2 2
A2 3
A3 1
A3 2
A3 3
In the following example, a DataPortal object loads data for a
two-dimensional set C:
model = AbstractModel()
model.C = Set(dimen=2)
data = DataPortal()
data.load(filename='C.tab', set=model.C)
instance = model.create_instance(data)
In this example, the column titles do not directly impact the process of loading data. Column titles can be used to select a subset of columns from a table that is loaded (see below).
Loading a Set Array
Consider the file D.tab, which defines an array representation of a
two-dimensional set:
B A1 A2 A3
1 + - -
2 - + -
3 - - +
In the following example, a DataPortal object loads data for a
two-dimensional set D:
model = AbstractModel()
model.D = Set(dimen=2)
data = DataPortal()
data.load(filename='D.tab', set=model.D, format='set_array')
instance = model.create_instance(data)
The format option indicates that the set data is declared in a array
format.
Loading Parameter Data
The param option is used specify a Param component that is
loaded with data.
Loading a Simple Parameter
The simplest parameter is simply a singleton value. Consider the file
Z.tab:
1.1
In the following example, a DataPortal object loads data for a simple
parameter z:
model = AbstractModel()
data = DataPortal()
model.z = Param()
data.load(filename='Z.tab', param=model.z)
instance = model.create_instance(data)
Loading an Indexed Parameter
An indexed parameter can be defined by a single column in a table. For
example, consider the file Y.tab:
A Y
A1 3.3
A2 3.4
A3 3.5
In the following example, a DataPortal object loads data for an indexed
parameter y:
model = AbstractModel()
data = DataPortal()
model.A = Set(initialize=['A1', 'A2', 'A3'])
model.y = Param(model.A)
data.load(filename='Y.tab', param=model.y)
instance = model.create_instance(data)
When column names are not used to specify the index and parameter data,
then the DataPortal
object assumes that the rightmost column defines parameter values. In
this file, the A column contains the index values, and the Y
column contains the parameter values.
Loading Set and Parameter Values
Note that the data for set A is predefined in the previous example.
The index set can be loaded with the parameter data using the index
option. In the following example, a DataPortal object loads data for set A
and the indexed parameter y
model = AbstractModel()
data = DataPortal()
model.A = Set()
model.y = Param(model.A)
data.load(filename='Y.tab', param=model.y, index=model.A)
instance = model.create_instance(data)
An index set with multiple dimensions can also be loaded with an indexed
parameter. Consider the file PP.tab:
A B PP
A1 B1 4.3
A2 B2 4.4
A3 B3 4.5
In the following example, a DataPortal object loads data for a tuple
set and an indexed parameter:
model = AbstractModel()
data = DataPortal()
model.A = Set(dimen=2)
model.p = Param(model.A)
data.load(filename='PP.tab', param=model.p, index=model.A)
instance = model.create_instance(data)
Loading a Parameter with Missing Values
Missing parameter data can be expressed in two ways. First, parameter
data can be defined with indices that are a subset of valid indices in
the model. The following example loads the indexed parameter y:
model = AbstractModel()
data = DataPortal()
model.A = Set(initialize=['A1', 'A2', 'A3', 'A4'])
model.y = Param(model.A)
data.load(filename='Y.tab', param=model.y)
instance = model.create_instance(data)
The model defines an index set with four values, but only three
parameter values are declared in the data file Y.tab.
Parameter data can also be declared with missing values using the period
(.) symbol. For example, consider the file S.tab:
A B PP
A1 B1 4.3
A2 B2 4.4
A3 B3 4.5
In the following example, a DataPortal object loads data for the index
set A and indexed parameter y:
model = AbstractModel()
data = DataPortal()
model.A = Set()
model.s = Param(model.A)
data.load(filename='S.tab', param=model.s, index=model.A)
instance = model.create_instance(data)
The period (.) symbol indicates a missing parameter value, but the
index set A contains the index value for the missing parameter.
Loading Multiple Parameters
Multiple parameters can be initialized at once by specifying a list (or
tuple) of component parameters. Consider the file XW.tab:
A X W
A1 3.3 4.3
A2 3.4 4.4
A3 3.5 4.5
In the following example, a DataPortal object loads data for parameters
x and w:
model = AbstractModel()
data = DataPortal()
model.A = Set(initialize=['A1', 'A2', 'A3'])
model.x = Param(model.A)
model.w = Param(model.A)
data.load(filename='XW.tab', param=(model.x, model.w))
instance = model.create_instance(data)
Selecting Parameter Columns
We have previously noted that the column names do not need to be
specified to load set and parameter data. However, the select
option can be to identify the columns in the table that are used to load
parameter data. This option specifies a list (or tuple) of column names
that are used, in that order, to form the table that defines the
component data.
For example, consider the following load declaration:
model = AbstractModel()
data = DataPortal()
model.A = Set()
model.w = Param(model.A)
data.load(filename='XW.tab', select=('A', 'W'), param=model.w, index=model.A)
instance = model.create_instance(data)
The columns A and W are selected from the file XW.tab, and a
single parameter is defined.
Loading a Parameter Array
Consider the file U.tab, which defines an array representation of a
multiply-indexed parameter:
I A1 A2 A3
I1 1.3 2.3 3.3
I2 1.4 2.4 3.4
I3 1.5 2.5 3.5
I4 1.6 2.6 3.6
In the following example, a DataPortal object loads data for a
two-dimensional parameter u:
model = AbstractModel()
data = DataPortal()
model.A = Set(initialize=['A1', 'A2', 'A3'])
model.I = Set(initialize=['I1', 'I2', 'I3', 'I4'])
model.u = Param(model.I, model.A)
data.load(filename='U.tab', param=model.u, format='array')
instance = model.create_instance(data)
The format option indicates that the parameter data is declared in a
array format. The format option can also indicate that the
parameter data should be transposed.
model = AbstractModel()
data = DataPortal()
model.A = Set(initialize=['A1', 'A2', 'A3'])
model.I = Set(initialize=['I1', 'I2', 'I3', 'I4'])
model.t = Param(model.A, model.I)
data.load(filename='U.tab', param=model.t, format='transposed_array')
instance = model.create_instance(data)
Note that the transposed parameter data changes the index set for the parameter.
Loading from Spreadsheets and Databases
Tabular data can be loaded from spreadsheets and databases using
auxiliary Python packages that provide an interface to these data
formats. Data can be loaded from Excel spreadsheets using the
win32com, xlrd and openpyxl packages. For example, consider
the following range of cells, which is named PPtable:
In the following example, a DataPortal object loads the named range
PPtable from the file excel.xls:
model = AbstractModel()
data = DataPortal()
model.A = Set(dimen=2)
model.p = Param(model.A)
data.load(filename='excel.xls', range='PPtable', param=model.p, index=model.A)
instance = model.create_instance(data)
Note that the range option is required to specify the table of cell
data that is loaded from the spreadsheet.
There are a variety of ways that data can be loaded from a relational database. In the simplest case, a table can be specified within a database:
model = AbstractModel()
data = DataPortal()
model.A = Set(dimen=2)
model.p = Param(model.A)
data.load(
filename='PP.sqlite', using='sqlite3', table='PPtable', param=model.p, index=model.A
)
instance = model.create_instance(data)
In this example, the interface sqlite3 is used to load data from an
SQLite database in the file PP.sqlite. More generally, an SQL query
can be specified to dynamically generate a table. For example:
model = AbstractModel()
data = DataPortal()
model.A = Set()
model.p = Param(model.A)
data.load(
filename='PP.sqlite',
using='sqlite3',
query="SELECT A,PP FROM PPtable",
param=model.p,
index=model.A,
)
instance = model.create_instance(data)
Data Namespaces
The DataPortal
class supports the concept of a namespace to organize data into named
groups that can be enabled or disabled during model construction.
Various DataPortal
methods have an optional namespace argument that defaults to
None:
data(name=None, namespace=None): Returns the data associated with data in the specified namespace[]: For aDataPortalobjectdata, the functiondata['A']returns data corresponding toAin the default namespace, anddata['ns1','A']returns data corresponding toAin namespacens1.namespaces(): Returns an iteratore for the data namespaces.keys(namespace=None): Returns an iterator of the data keys in the specified namespace.values(namespace=None): Returns and iterator of the data values in the specified namespace.items(namespace=None): Returns an iterator of (name, value) tuples in the specified namespace.
By default, data within a namespace are ignored during model construction. However, concrete models can be initialized with data from a specific namespace. Further, abstract models can be initialized with a list of namespaces that define the data used to initialized model components. For example, the following script generates two model instances from an abstract model using data loaded into different namespaces:
model = AbstractModel()
model.C = Set(dimen=2)
data = DataPortal()
data.load(filename='C.tab', set=model.C, namespace='ns1')
data.load(filename='D.tab', set=model.C, namespace='ns2', format='set_array')
instance1 = model.create_instance(data, namespaces=['ns1'])
instance2 = model.create_instance(data, namespaces=['ns2'])